Kappa
“Great things are not done by impulse, but by a series of small things brought together.”
Hack The Box
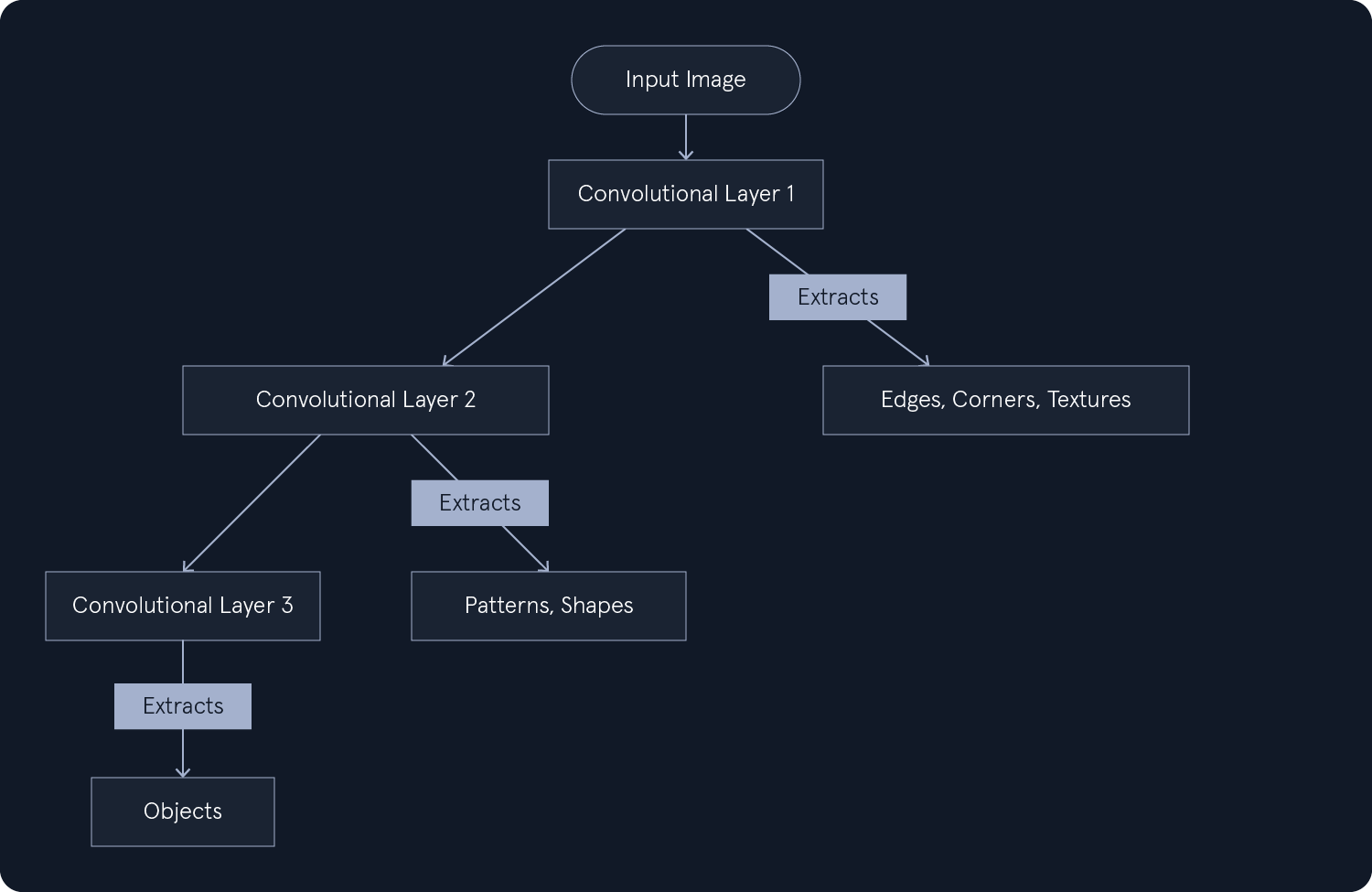
Convolutional Neural Networks
Convolutional Neural Networks (CNNs) are specialized neural networks designed for processing grid-like data, such as images. They excel at capturing spatial hierarchies of features, making them highly effective for tasks like image recognition, object detection, and image segmentation.
A typical CNN consists of three main types of layers:
- Convolutional Layers: - These are the core building blocks of a CNN. They perform convolutions on the input data using a set of learnable filters. Each filter slides across the input, computing the dot product between the filter weights and the input values at each position. This process extracts features from the input, such as edges, corners, and textures. The output of a convolutional layer is a feature map, which highlights the presence of the learned features in the input. Multiple filters are used in each layer to detect different types of features.
- Pooling Layers: - These layers reduce the dimensionality of the feature maps, making the network less computationally expensive and less susceptible to overfitting. They operate on each feature map independently, downsampling it by taking the maximum or average value within a small window. Common types of pooling include max pooling and average pooling.
- Fully Connected Layers: - These layers are similar to those in MLPs. They connect every neuron in one layer to every neuron in the next layer. These layers are typically used towards the network's end to perform high-level reasoning and make predictions based on the extracted features.
Convolutional and pooling layers are stacked alternately to create a hierarchy of features. The output of the final pooling layer is then flattened and fed into one or more fully connected layers for classification or regression.
This layered structure lets CNNs learn complex patterns and representations from image data. The convolutional layers extract local features, the pooling layers downsample and aggregate these features, and the fully connected layers combine the high-level features to make predictions.
Feature Maps and Hierarchical Feature Learning
In a CNN, feature maps are generated by the convolutional layers. Each convolutional filter produces a corresponding feature map, highlighting the locations and strength of specific visual patterns within the input image. For example, one filter might detect edges, another corners, and another texture.
{kind=link}
The network learns these features by adjusting filter weights during training. As it is exposed to more data, it refines these filters to become detectors for increasingly complex visual elements.
This learning process is hierarchical:
- Initial Layers: - These layers tend to learn simple, low-level features like edges and blobs. For example, a convolutional layer might detect vertical or horizontal edges in an image.
- Intermediate Layers: - As the network progresses, subsequent layers combine these basic features to detect more complex patterns. For instance, one intermediate layer might identify corners by combining edge detections from earlier layers.
- Deeper Layers: - These layers learn high-level features such as shapes and object parts. For example, a deep convolutional layer might recognize wheels, windows, or entire cars in an image recognition task.
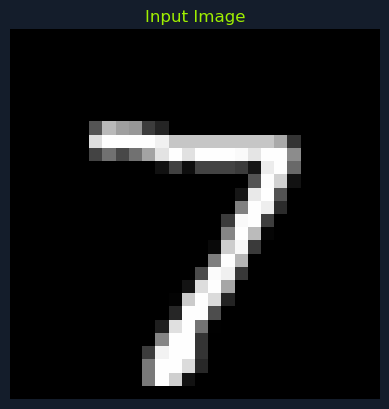
To illustrate this hierarchical feature extraction, consider the handwritten digit "7". The input image is processed through multiple convolutional layers, each extracting different levels of features.
{kind=link}
The first convolutional layer focuses on low-level features such as edges and borders. For example, it might detect the vertical and horizontal edges that form the digit "7".
{kind=link}
In this image, you can clearly see a focus on the border and edges of the number 7. The filter has highlighted the sharp transitions in intensity, which correspond to the boundaries of the digit.
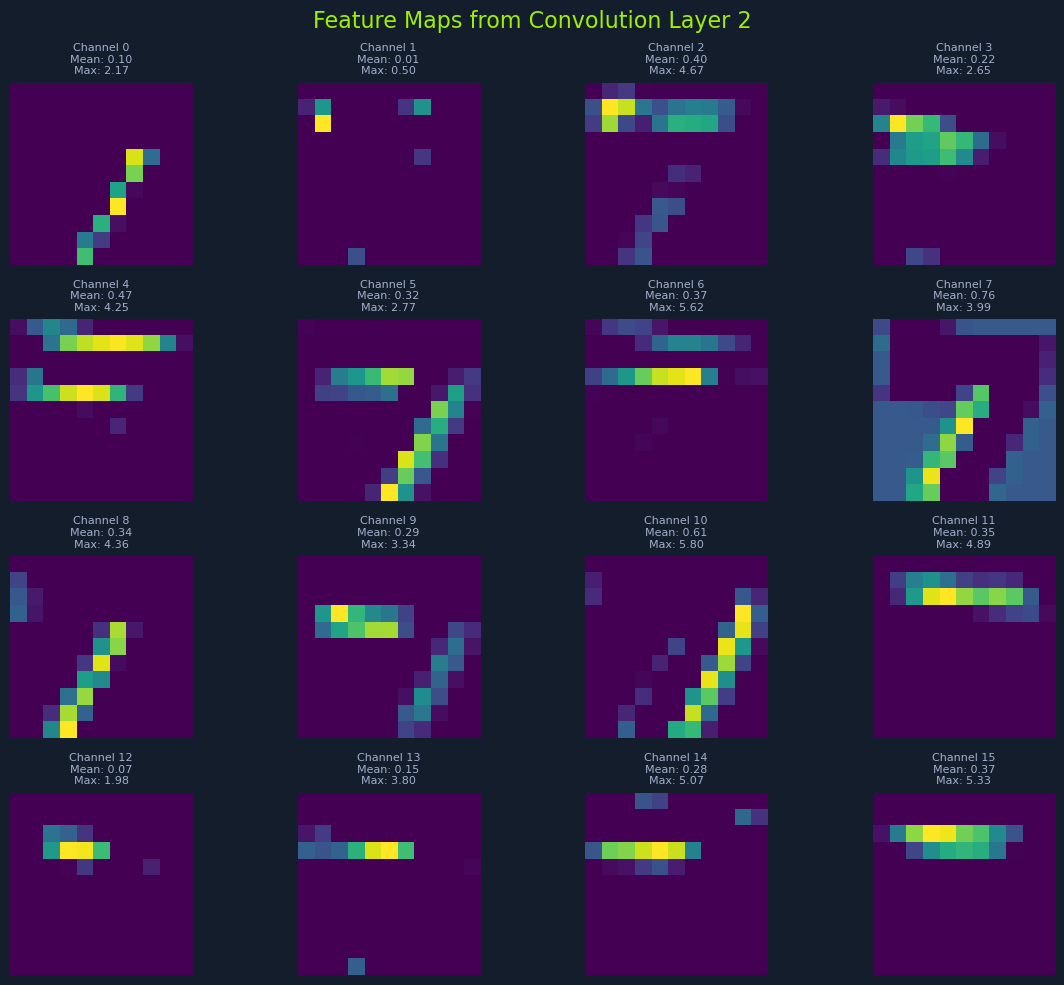
The second convolutional layer builds upon the features extracted by the first layer. It combines these edge detections to identify more complex patterns, such as the interior structure of the digit.
{kind=link}
Here, you can see a focus on the inside of the number 7, rather than just the edges. The filter has detected the continuous lines and curves that form the digit, providing a more detailed representation.
This hierarchical feature extraction allows CNNs to represent complex visual information in a structured and efficient manner. By building upon the features learned in earlier layers, deeper layers can capture increasingly abstract and meaningful representations of the input data. This is why CNNs are so effective at tasks that require understanding complex visual scenes, such as image classification, object detection, and segmentation.
Image Recognition
{kind=link}
To illustrate this process, consider an image recognition task where a CNN is trained to classify images of different animals:
- Input Layer: - The input is a raw image, typically represented as a 3D tensor (height, width, channels).
- Convolutional Layers:
- Layer 1: Detects low-level features like edges and simple textures.
- Layer 2: Combines these features to detect more complex patterns, such as corners and curves.
- Layer 3: Recognizes higher-level structures like shapes and object parts.
- Pooling Layers:- Reduce the spatial dimensions of the feature maps, making the network less computationally expensive and more robust to small translations in the input image.
- Fully Connected Layers:
- Flatten the output from the final pooling layer.
- Perform high-level reasoning and make predictions based on the extracted features, such as classifying the image as a cat, dog, or bird.
By stacking these layers, CNNs can learn to recognize complex visual patterns and make accurate predictions. This hierarchical structure is key to their success in various computer vision tasks.
Data Assumptions for a CNN
While Convolutional Neural Networks (CNNs) have proven to be powerful tools for image recognition and other computer vision tasks, their effectiveness relies on certain assumptions about the input data. Understanding these assumptions is crucial for ensuring optimal performance and avoiding potential pitfalls.
Grid-Like Data Structure
CNNs are inherently designed to work with data structured as grids. This grid-like organization is fundamental to how CNNs process information. Common examples include:
- Images: Represented as 2D grids, where each grid cell holds a pixel value. The dimensions typically include height, width, and channels (e.g., red, green, blue).
- Videos: Represented as 3D grids, extending the image concept by adding a time dimension. This results in a height, width, time, and channel structure.
The grid structure is crucial because it allows CNNs to leverage localized convolutional operations, which we'll discuss later.
Spatial Hierarchy of Features
CNNs operate under the assumption that features within the data are organized hierarchically. This means that:
- Lower-level features like edges, corners, or textures are simple and localized. They are typically captured in the network's early layers.
- Higher-level features are more complex and abstract, built upon these lower-level features. They represent larger patterns, shapes, or even entire objects and are detected in the deeper layers of the network.
This hierarchical feature extraction is a defining characteristic of CNNs, enabling them to learn increasingly complex representations of the input data.
Feature Locality
CNNs exploit the principle of feature locality, which assumes that relevant relationships between data points are primarily confined to local neighborhoods. For instance:
- In images, neighboring pixels are more likely to be correlated and form meaningful patterns than pixels far apart.
- Convolutional filters, the core building blocks of CNNs, are designed to focus on small local regions of the input (called receptive fields). This allows the network to capture these local dependencies efficiently.
Feature Stationarity
Another important assumption is feature stationarity, which implies that the meaning or significance of a feature remains consistent regardless of its location within the input data.
This means that a feature, such as a vertical edge, should be recognized as the same feature, whether on the image's left, right, or center.
CNNs achieve this through weight sharing in convolutional layers. The same filter is applied across all positions in the input, enabling the network to detect the same feature anywhere in the data.
Sufficient Data and Normalization
Effective training of CNNs relies on two practical considerations:
- Sufficient data: - CNNs, like most deep learning models, are data-hungry. They require large, labeled datasets to learn complex patterns and generalize to unseen data. Insufficient data can lead to overfitting, where the model performs well on training data but poorly on new data.
- Normalized input: - Input data should be normalized to a standard range (e.g., scaling pixel values to between 0 and 1, or -1 and 1). This ensures stable and efficient training by preventing large variations in input values from disrupting the learning process.
Adhering to these assumptions has proven remarkably successful in various tasks, including image classification, object detection, and natural language processing. Understanding these assumptions is crucial for designing, training, and deploying effective CNN models.
Fundamentals of AI
- Introduction to Machine Learning
- Mathematics Refresher for AI
- Supervised Learning Algorithms
- Linear Regression
- Logistic Regression
- Decision Trees
- Naive Bayes
- Support Vector Machines (SVMs)
- Unsupervised Learning Algorithms
- K-Means Clustering
- Principal Component Analysis (PCA)
- Anomaly Detection
- Reinforcement Learning Algorithms
- Q-Learning
- SARSA (State-Action-Reward-State-Action)
- Introduction to Deep Learning
- Perceptrons
- Neural Networks
- ~ Convolutional Neural Networks
- Recurrent Neural Networks